




前言
采用zabbix监控交换机流量,经常出现获取数据超时。但是通过snmpwalk是可以获取数据。原先通过snmpv3解决了这个问题。最近又出现了,而找不到原因。研究了一下prometheus+grafana通过snmp-exporter获取交换机数据,作为zabbix的补充。
部署过程
基本环境
docker和docker-compose的安装参考docker和docker-compose一键安装脚本
docker-compose.yml
项目启动配置文件
version: "3.8"
networks:
net:
driver: bridge
services:
snmp-exporter:
image: prom/snmp-exporter:latest
container_name: ly-monitor-snmp-exporter
restart: always
ports:
- "9116:9116"
volumes:
- "./myapp/snmp/snmp.yml:/etc/snmp_exporter/snmp.yml"
networks:
- net
prometheus:
image: prom/prometheus:latest
container_name: ly-monitor-prometheus
restart: always
user: "0"
ports:
- "9090:9090"
volumes:
- "./myapp/prometheus/:/prometheus"
command:
- "--storage.tsdb.retention.time=180d"
- "--config.file=/prometheus/prometheus.yml"
- "--web.enable-lifecycle"
networks:
- net
depends_on:
- snmp-exporter
grafana:
image: grafana/grafana:latest
restart: always
container_name: ly-monitor-grafana
user: "0"
ports:
- "3000:3000"
environment:
- "GF_SECURITY_ADMIN_PASSWORD=xxxxxx" #grafana登录密码,自己设置
- "GF_RENDERING_SERVER_URL=http://renderer:8081/render"
- "GF_RENDERING_CALLBACK_URL=http://grafana:3000/"
- "GF_LOG_FILTERS=rendering:debug"
volumes:
- ./data/grafana/:/var/lib/grafana
networks:
- net
depends_on:
- prometheus
- renderer
renderer:
image: grafana/grafana-image-renderer:latest
container_name: ly-monitor-renderer
ports:
- "8081:8081"
environment:
- "ENABLE_METRICS=true"
- "RENDERING_MODE=clustered"
- "RENDERING_CLUSTERING_MODE=context"
- "RENDERING_CLUSTERING_MAX_CONCURRENCY=5"
networks:
- netsnmp-exporter配置
配置文件snmp.yml,需要根据交换机mib自己生成。
- Dockerfile
FROM golang:latest
RUN sed -i "s@http://deb.debian.org@http://mirrors.aliyun.com@g" /etc/apt/sources.list && \
rm -Rf /var/lib/apt/lists/* && \
apt-get update && \
apt-get install -y libsnmp-dev p7zip-full unzip
ENV GO111MODULE on
ENV GOPROXY https://goproxy.cn
RUN go install github.com/prometheus/snmp_exporter/generator@latest
WORKDIR "/opt"- generator.yml
modules:
H3C:
walk:
- 1.3.6.1.2.1.1.1 #sysDescr
- 1.3.6.1.2.1.1.3 #sysUpTimeInstance
- 1.3.6.1.2.1.1.5 #sysName
- 1.3.6.1.2.1.2.2.1.1 #ifIndex
- 1.3.6.1.2.1.2.2.1.2 #IfDescr
- 1.3.6.1.2.1.31.1.1.1.1 #ifName
- 1.3.6.1.2.1.31.1.1.1.6 #ifHCInOctets
- 1.3.6.1.2.1.31.1.1.1.10 #ifHCOutOctets
- 1.3.6.1.2.1.47.1.1.1.1.2 #entPhysicalDescr
- 1.3.6.1.2.1.47.1.1.1.1.5 #entPhysicalClass
- 1.3.6.1.2.1.47.1.1.1.1.7 #entPhysicalName
- 1.3.6.1.4.1.25506.2.6.1.1.1.1.6 #hh3cEntityExtCpuUsage
- 1.3.6.1.4.1.25506.2.6.1.1.1.1.8 #hh3cEntityExtMemUsage
- 1.3.6.1.4.1.25506.2.6.1.1.1.1.12 #hh3cEntityExtTemperature
- 1.3.6.1.4.1.25506.8.35.9.1.1.1.2 #hh3cDevMFanStatus
- 1.3.6.1.4.1.25506.8.35.9.1.2.1.2 #hh3cDevMPowerStatus
max_repetitions: 3
retries: 3
timeout: 25s
version: 3
auth:
username: hcuser
password: hcpass234
auth_protocol: SHA
priv_protocol: DES
priv_password: hcdes234
security_level: authPriv
lookups:
- source_indexes: [ifIndex]
lookup: 1.3.6.1.2.1.2.2.1.2 # ifDescr
- source_indexes: [ifIndex]
lookup: 1.3.6.1.2.1.31.1.1.1.1 # ifName
- source_indexes: [hh3cEntityExtPhysicalIndex]
lookup: 1.3.6.1.2.1.47.1.1.1.1.2 #entPhysicalDescr
- source_indexes: [hh3cEntityExtPhysicalIndex]
lookup: 1.3.6.1.2.1.47.1.1.1.1.5 #entPhysicalClass
- source_indexes: [hh3cEntityExtPhysicalIndex]
lookup: 1.3.6.1.2.1.47.1.1.1.1.7 #entPhysicalName
overrides:
ifAlias:
ignore: true # Lookup metric
ifDescr:
ignore: true # Lookup metric
ifName:
ignore: true # Lookup metric
entPhysicalDescr:
ignore: true # Lookup metric
entPhysicalName:
ignore: true # Lookup metric
entPhysicalClass:
ignore: true # Lookup metricprometheus.yaml
Prometheus的主配置文件
# my global config
global:
scrape_interval: 60s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 60s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'snmp'
scrape_timeout: 30s # 采集超时10s
scrape_interval: 1m # 采集频率1m
static_configs:
- targets:
- 10.10.10.62 #交换机ip
metrics_path: /snmp
params:
module: [H3C] #修改成2.4步自己设置的mib名称
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: snmp-exporter:9116 # 安装snmp_exporter主机的ip和端口号snmp.yml生成
#构建镜像
cd src/generator/ && docker build -t generator . && cd -
#获取mibs并放到 .src/generator/mibs 目录下
#生成snmp.yaml
docker run -it --rm -v /opt/ly-monitor/src/:/opt --privileged generator /bin/bash
export MIBDIRS=/opt/generator/mibs
cd generator/ && generator generate
exit
#移动到目标位置
/bin/cp -f src/generator/snmp.yml myapp/snmp/启动服务
docker-compose up -d访问
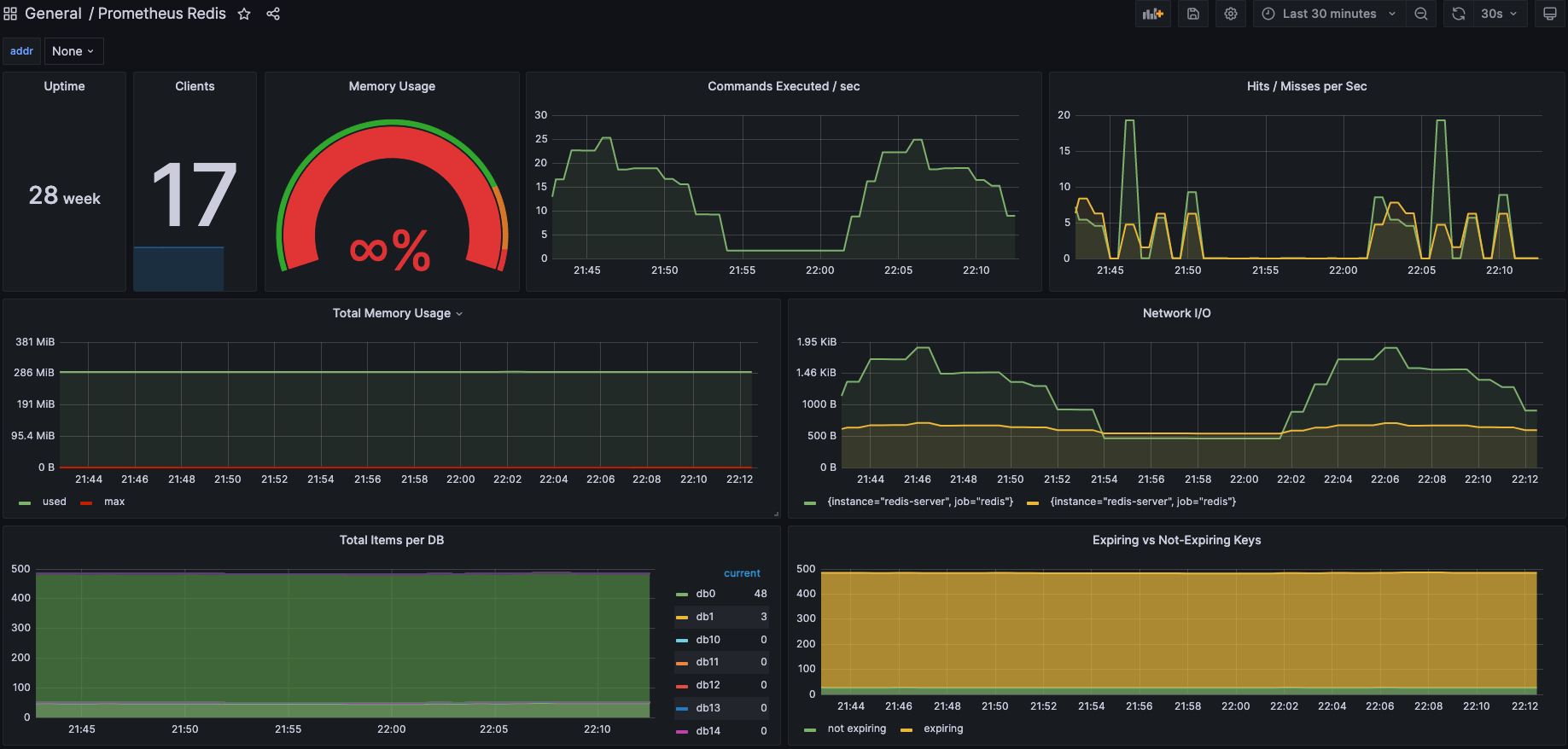
通过浏览器访问http://ip:3000/login

FAQ
snmp_exporter获取数据报错

snmpwalk -v 3 -t 2 -u hcuser -l authPriv -a sha -A hcxxxx234 -x des -X hcyyyy234 192.168.4.62 ifAlias
喜欢这篇文章,作者666,文章真棒!
这篇文章肯定会火,作者666大顺学习到了,感谢博主
学习到了,感谢博主
这篇文章肯定会火,作者666大顺
666666
喜欢这篇文章,作者666,文章真棒!
学习到了 thx
对小白真的很友好,写的很全面。
写得非常好
对小白真的很友好,写的很全面。