




前言
Redis运维和监控的意义很重要,需要从三个方面去构建认知体系。
- 首先Redis自身提供了哪些状态信息,以及有哪些常见的命令可以获取Redis的监控信息。
- 其次需要知道一些常见的UI工具可视化监控Redis。
- 最后需要理解Reids的监控体系。
自身状态及命令
如果只是想简单看一下Redis负载情况的话,完全可以用它本身提供的一些命令来完成。
info
Redis提供的INFO命令不仅能够查看实时的吞吐量(ops/sec),还能看到一些有用的运行时信息。
info查看所有状态信息
redis-cli -h 127.0.0.1
> info
# Server
redis_version:3.2.12 #版本号
redis_git_sha1:00000000 #摘要
redis_git_dirty:0 #dirty标识
redis_build_id:7897e7d0e13773f #构建id
redis_mode:standalone #运行模式
os:Linux 3.10.0-1127.19.1.el7.x86_64 x86_64 #宿主操作系统
arch_bits:64 #服务器cpu架构
multiplexing_api:epoll #io机制
gcc_version:4.8.5 #gcc版本
process_id:18894 #当前进程id
run_id:f1e39689047298be9c7593b1b9830708fdddbdfc #服务器随机标识
tcp_port:6379 #监听端口
uptime_in_seconds:16843337 #运行时间
uptime_in_days:194 #运行天数
hz:10 #内部调度频率,每秒10次
lru_clock:3390935 #自增时钟
executable:/usr/bin/redis-server #主程序目录
config_file:/etc/redis.conf #配置文件
# Clients
connected_clients:24 #已连接客户端
client_longest_output_list:0 #当前连接的客户端,最长输出列表
client_biggest_input_buf:0 #当前连接客户端,最大输入缓存
blocked_clients:1 #等待组塞命令的客户端数量
# Memory
used_memory:305246248 #分配内存总量,byte为单位
used_memory_human:291.11M #以可读格式返回的redis内存总量
used_memory_rss:304226304 #常驻集大小,这个值和top,ps输出一致
used_memory_rss_human:290.13M #内存消耗峰值
used_memory_peak:312258640
used_memory_peak_human:297.79M
total_system_memory:3973308416
total_system_memory_human:3.70G
used_memory_lua:39936
used_memory_lua_human:39.00K #lua脚本存储占用的内存
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.00
mem_allocator:jemalloc-3.6.0
# Persistence
loading:0 #服务器是否正在载入持久化文件,0表示没有
rdb_changes_since_last_save:26 #多少写入命令未持久化
rdb_bgsave_in_progress:0 #服务器是否正在创建rdb文件,0表示否
rdb_last_save_time:1681112503 #最后一次成功创建rdb文件的时间戳
rdb_last_bgsave_status:ok #最近一次持久化是否成功
rdb_last_bgsave_time_sec:0 #最近一次成功创建rdb消耗时间
rdb_current_bgsave_time_sec:-1 #当前正在创建rdb已消耗秒数
aof_enabled:0 #是否开启了aof
aof_rewrite_in_progress:0 #标识aof的rewrite操作是否在进行中
aof_rewrite_scheduled:0 #rewrite任务计划
aof_last_rewrite_time_sec:-1 #最近一次aof rewrite耗费的时长
aof_current_rewrite_time_sec:-1 #如果rewrite操作正在进行,则记录所使用的时间,单位秒
aof_last_bgrewrite_status:ok #上次bgrewriteaof操作的状态
aof_last_write_status:ok #上次aof写入状态
# Stats
total_connections_received:411841 #服务器已经接受的连接请求数量
total_commands_processed:150314863 #redis处理的命令数
instantaneous_ops_per_sec:33 #redis当前的qps,redis内部较实时的每秒执行的命令数
total_net_input_bytes:11031778421 #redis网络入口流量字节数
total_net_output_bytes:2870334736 #redis网络出口流量字节数
instantaneous_input_kbps:2.29 #redis网络入口kps
instantaneous_output_kbps:0.61 #redis网络出口kps
rejected_connections:0 #拒绝的连接个数,redis连接个数达到maxclients限制,拒绝新连接的个数
sync_full:0 #主从完全同步成功次数
sync_partial_ok:0 #主从部分同步成功次数
sync_partial_err:0 #主从部分同步失败次数
expired_keys:51092 #运行以来过期的key的数量
evicted_keys:0 #运行以来剔除(超过了maxmemory后)的key的数量
keyspace_hits:50784538 #命中次数
keyspace_misses:16770207 #没命中次数
pubsub_channels:0 #当前使用中的频道数量
pubsub_patterns:2 #当前使用的模式的数量
latest_fork_usec:5910 #最近一次fork操作阻塞redis进程的耗时数,单位微秒
migrate_cached_sockets:0 #是否已经缓存了到该地址的连接
# Replication
role:master #实例的角色,是master or slave
connected_slaves:0 #连接的slave实例个数
master_repl_offset:0 #主从同步偏移量,此值如果和上面的offset相同说明主从一致没延迟,与master_replid可被用来标识主实例复制流中的位置
repl_backlog_active:0 #复制积压缓冲区是否开启
repl_backlog_size:1048576 #复制积压缓冲大小
repl_backlog_first_byte_offset:0 #复制缓冲区里偏移量的大小
repl_backlog_histlen:0 #此值等于 master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小
# CPU
used_cpu_sys:12016.05 #将所有redis主进程在核心态所占用的CPU时求和累计起来
used_cpu_user:10008.11 #将所有redis主进程在用户态所占用的CPU时求和累计起来
used_cpu_sys_children:1310.63 #将后台进程在核心态所占用的CPU时求和累计起来
used_cpu_user_children:30229.96 #将后台进程在用户态所占用的CPU时求和累计起来
# Cluster
cluster_enabled:0
# Keyspace
db0:keys=55,expires=30,avg_ttl=335475220
db1:keys=3,expires=0,avg_ttl=0
db2:keys=433,expires=433,avg_ttl=42248758
查看某个section的信息
> info memorymonitor
monitor用来监视服务端收到的命令。

监控延迟
观测延迟
redis-cli --latency -h 127.0.0.1度量延迟
redis-cli --intrinsic-latency 100 -h 127.0.0.1
可视化监控工具
在谈Redis可视化监控工具时,要分清工具到底是仅仅指标的可视化,还是可以融入监控体系(比如包含可视化,监控,报警等),这是生产环境长期监控生态的基础。
- 只能可视化指标不能监控: redis-stat、RedisLive、redmon等工具
- 用于生产环境:基于redis_exporter以及grafana可以做到指标可视化,持久化,监控以及报警等
redis-stat
redis-stat是一个比较有名的redis指标可视化监控工具,采用ruby开发,基于reids的info和monitor命令来统计,不影响reids性能
docker run --name redis-stat -p 6380:63790 -d insready/redis-stat --server 172.17.0.10:6379
RedisLive
采用python开发的redis的可视化及查询分析工具
# 启动
docker run --name redis-live -p 8888:8888 -d snakeliwei/redislive
# 编辑配置
docker exec -it redis-live vi redis-live.conf访问
http://ip:8888/index.html

redmon
redmon提供了cli、admin的web界面,同时也能够实时监控redis
# 启动
docker run -p 4567:4567 -d vieux/redmon -r redis://172.17.0.10:6379


redis_exporter
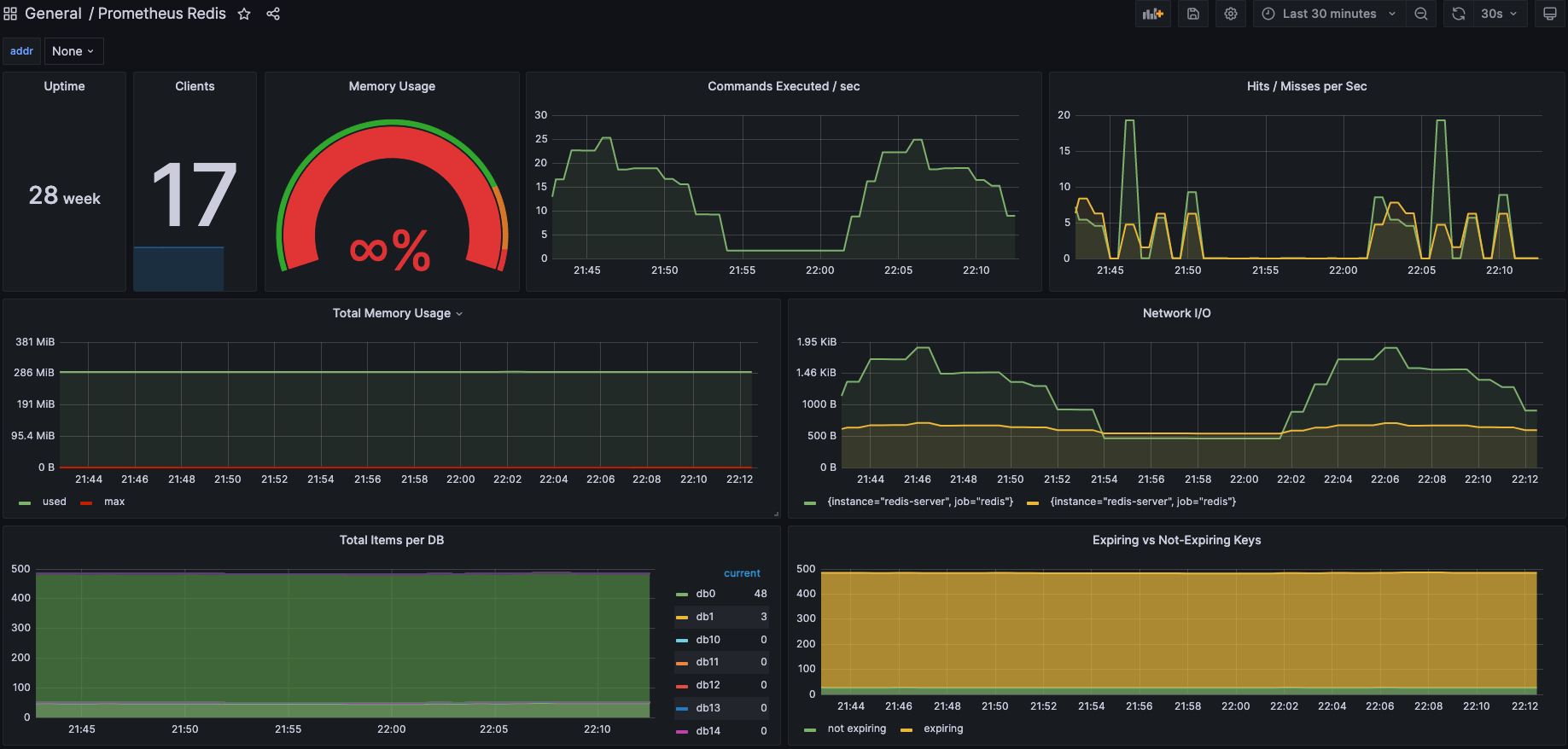
为Prometheus提供了redis指标的exporter,支持Redis 2.x, 3.x, 4.x, 5.x, and 6.x,配合Prometheus以及grafana的Prometheus Redis插件,可以在grafana进行可视化及监控

监控体系
监控体系到底应该考虑什么?redis这类敏感的纯内存、高并发和低时延的服务,一套完善的监控告警方案,是精细化运营的前提。
什么样的场景需要
一个大型系统引入了Redis作为缓存中间件,具体描述如下:
- 部署架构采用Redis-Cluster模式;
- 后台应用系统有几十个,应用实例数超过二百个;
- 所有应用系统共用一套缓存集群;
- 集群节点数几十个,加上容灾备用环境,节点数量翻倍;
- 集群节点内存配置较高。

系统刚开始关于Redis的一切都很正常,随着应用系统接入越来越多,应用系统子模块接入也越来越多,开始出现一些问题,应用系统有感知,集群服务端也有感知:
- 集群节点崩溃
- 集群节点假死
- 某些后端应用访问集群响应特别慢
其实问题的根源都是架构运维层面的欠缺,对于Redis集群服务端的运行监控其实很好做,上面也介绍了很多直接的命令方式,但只能看到服务端的一些常用指标信息,无法深入分析,治标不治本,对于Redis的内部运行一无所知,特别是对于业务应用如何使用Redis集群一无所知:
- Redis集群使用的热度问题
- 哪些应用占用的Redis内存资源多
- 哪些应用占用Redis访问数最高
- 哪些应用使用Redis类型不合理
- 应用系统模块使用Redis资源分布怎么样
- 应用使用Redis集群的热点问题
监控体系的价值
Redis监控告警的价值对每个角色都不同,重要的几个方面:
- redis故障快速通知,定位故障点;
- 分析redis故障的Root cause;
- redis容量规划和性能管理;
- redis硬件资源利用率和成本
redis故障快速发现,定位故障点和解决故障
当redis出现故障时,运维人员应在尽可能短时间内发现告警;如果故障对服务是有损的(如大面积网络故障或程序BUG),需立即通知SRE和RD启用故障预案(如切换机房或启用emergency switch)止损。
如果没完善监控告警; 假设由RD发现服务故障,再排查整体服务调用链去定位;甚于用户发现用问题,通过客服投诉,再排查到redis故障的问题;整个redis故障的发现、定位和解决时间被拉长,把一个原本的小故障被"无限"放大。#
分析redis故障的Root cause
任何一个故障和性能问题,其根本“诱因”往往只有一个,称为这个故障的Root cause。一个故障从DBA发现、止损、分析定位、解决和以后规避措施;最重要一环就是DBA通过各种问题表象,层层分析到Root cause;找到问题的根据原因,才能根治这类问题,避免再次发生。完善的redis监控数据,是我们分析root cause的基础和证据。问题表现是综合情的,一般可能性较复杂,这里举2个例子:
- 服务调用Redis响应时间变大的性能总是;可能网络问题,redis慢查询,redis QPS增高达到性能瓶颈,redis fork阻塞和请求排队,redis使用swap, cpu达到饱和(单核idle过低),aof fsync阻塞,网络进出口资源饱和等等
- redis使用内存突然增长,快达到maxmemory; 可能其个大键写入,键个数增长,某类键平均长度突增,fork COW, 客户端输入/输出缓冲区,lua程序占用等等
Root cause是要直观的监控数据和证据,而非有技术支撑的推理分析。
- redis响应抖动,分析定位root casue是bgsave时fork导致阻塞200ms的例子。而不是分析推理:redis进程rss达30gb,响应抖动时应该有同步,fork子进程时,页表拷贝时要阻塞父进程,估计页表大小xx,再根据内存copy连续1m数据要xx 纳秒,分析出可能fork阻塞导致的。
Redis容量规划和性能管理
通过分析redis资源使用和性能指标的监控历史趋势数据;对集群进行合理扩容(Scale-out)、缩容(Scale-back);对性能瓶颈优化处理等。Redis资源使用饱和度监控,设置合理阀值;一些常用容量指标:redis内存使用比例,swap使用,cpu单核的饱和度等;当资源使用容量预警时,能及时扩容,避免因资源使用过载,导致故障。另一方面,如果资源利用率持续过低,及时通知业务,并进行redis集群缩容处理,避免资源浪费。进一步,容器化管理redis后,根据监控数据,系统能自动地弹性扩容和缩容。Redis性能监控管理,及时发现性能瓶颈,进行优化或扩容,把问题扼杀在萌芽期,避免它进化成故障。
Redis硬件资源利用率和成本
从老板角度来看,最关心的是成本和资源利用率是否达标。如果资源不达标,就得推进资源优化整合;提高硬件利用率,减少资源浪费。砍预算,减成本。资源利用率是否达标的数据,都是通过监控系统采集的数据。
监控体系的维度
监控的目的不仅仅是监控Redis本身,而是为了更好的使用Redis。传统的监控一般比较单一化,没有系统化,但对于Redis来说,个人认为至少包括:一是服务端,二是应用端,三是服务端与应用端联合分析。
- 服务端首先是操作系统层面,常用的CPU、内存、网络IO,磁盘IO,服务端运行的进程信息等;
- Redis运行进程信息,包括服务端运行信息、客户端连接数、内存消耗、持久化信息 、键值数量、主从同步、命令统计、集群信息等;
- Redis运行日志,日志中会记录一些重要的操作进程,如运行持久化时,可以有效帮助分析崩溃假死的程序。#
具体的监控指标
redis监控的数据采集,数据采集1分钟一次,分为下面几个方面:
- 服务器系统数据采集
- Redis Server数据采集
- Redis响应时间数据采集
- Redis监控Screen
服务器系统监控数据采集,这部分包含数百个指标. 采集方式现在监控平台自带的agent都会支持我们从redis使用资源的特性,分析各个子系统的重要监控指标。
- 存活监控,ping监控报警
- CPU,平均负载,整体利用率,单核饱和度,上下文切换
- 内存和swap,内存余量大小和swap使用量大小
- 磁盘,使用率和IOPS的饱和度
- 网络,吞吐量饱和度和丢包率
Redis Server监控数据采集,通过redis实例的状态数据采集
- 存活监控,redis存活监控和uptime监控
- 连接数监控,连接个数、连接数使用率、新创建连接个数、list阻塞调用
- 内存监控,内存分配大小,内存使用比例,进程使用内存大小,内存碎片率
Redis综合性能监控
- Redis Keyspace: redis键空间的状态监控
- Redis qps
- Redis cmdstat_xxx
- Redis Keysapce hit ratio
- Redis fork
Redis慢查询监控
redis慢查询是排查性能问题关键监控指标。因redis是单线程模型(single-threaded server), 即一次只能执行一个命令,如果命令耗时较长,其他命令就会被阻塞,进入队列排队等待;这样对程序性能会较大。
redis慢查询保存在内存中,最多保存slowlog-max-len(默认128)个慢查询命令,当慢查询命令日志达到128个时,新慢查询被加入前,会删除最旧的慢查询命令。因慢查询不能持久化保存,且不能实时监控每秒产生的慢查询个数。
- 设置合理慢查询日志阀值,slowlog-log-slower-than, 建议1ms(如果平均1ms, redis qps也就只有1000) 设+ 置全理慢查询日志队列长度,slowlog-max-len建议大于1024个,因监控采集周期1分钟,建议,避免慢查询日志被删除;另外慢查询的参数过多时,会被省略,对内存消耗很小
- 每次采集使用slowlog len获取慢查询日志个数
- 每次彩集使用slowlog get 1024 获取所慢查询,并转存储到其他地方,如MongoDB或MySQL等,方便排查问题;并分析当前慢查询日志最长耗时微秒数。
- 然后使用slowlog reset把慢查询日志清空,下个采集周期的日志长度就是最新产生的。
- redis慢查询日志个数 (slowlog_len):每个采集周期出现慢查询个数,如1分钟出现10次大于1ms的慢查询
- redis慢查询日志最长耗时值 (slowlog_max_time):获取慢查询耗时最长值,因有的达10秒以下的慢查询,可能导致复制中断,甚至出来主从切换等故障。#
Redis持久化监控
保障数据落地,减少故障时数据丢失。这里分析redis rdb数据持久化的几个监控指标。
- 最近一次rdb持久化是否成功 (rdb_last_bgsave_status):如果持久化未成功,建议告警,说明备份或主从复制同步不正常。或redis设置有“stop-writes-on-bgsave-error”为yes,当save失败后,会导致redis不能写入操作
- 最近一次成功生成rdb文件耗时秒数 (rdb_last_bgsave_time_sec):rdb生成耗时反应同步时数据是否增长; 如果远程备份使用redis-cli –rdb方式远程备份rdb文件,时间长短可能影响备份线程客户端输出缓冲内存使用大小。
- 离最近一次成功生成rdb文件,写入命令的个数 (rdb_changes_since_last_save):即有多少个写入命令没有持久化,最坏情况下会丢失的写入命令数。建议设置监控告警离
- 最近一次成功rdb持久化的秒数 (rdb_last_save_time): 最坏情况丢失多少秒的数据写入。使用当前时间戳 - 采集的rdb_last_save_time(最近一次rdb成功持久化的时间戳),计算出多少秒未成功生成rdb文件
Redis复制监控
不论使用何种redis集群方案, redis复制 都会被使用。复制相关的监控告警项:
- redis角色 (redis_role):实例的角色,是master or slave
- 复制连接状态 (master_link_status): slave端可查看它与master之间同步状态;当复制断开后表示down,影响当前集群的可用性。需设置监控告警。
- 复制连接断开时间长度 (master_link_down_since_seconds):主从服务器同步断开的秒数,建议设置时长告警。
- 主库多少秒未发送数据到从库 (master_last_io_seconds):如果主库超过repl-timeout秒未向从库发送命令和数据,会导致复制断开重连。 在slave端可监控,建议设置大于10秒告警
- 从库多少秒未向主库发送REPLCONF命令 (slave_lag): 正常情况从库每秒都向主库,发送REPLCONF ACK命令;如果从库因某种原因,未向主库上报命令,主从复制有中断的风险。通过在master端监控每个slave的lag值。
- 从库是否设置只读 (slave_read_only):从库默认只读禁止写入操作,监控从库只读状态;如果关闭从库只读,有写入数据风险。
- 主库挂载的从库个数 (connected_slaves):主库至少保证一个从库,不建议设置超过2个从库。
- 复制积压缓冲区是否开启 (repl_backlog_active):主库默认开启复制积压缓冲区,用于应对短时间复制中断时,使用 部分同步 方式。
- 复制积压缓冲大小 (repl_backlog_size):主库复制积压缓冲大小默认1MB,因为是redis server共享一个缓冲区,建议设置100MB.
Redis集群监控
这里所写 redis官方集群方案 的监控指标,数据基本通过cluster info和info命令采集。
- 实例是否启用集群模式 (cluster_enabled): 通过info的cluster_enabled监控是否启用集群模式。
- 集群健康状态 (clusster_state):如果当前redis发现有failed的slots,默认为把自己cluster_state从ok个性为fail, 写入命令会失败。如果设置cluster-require-full-coverage为NO,则无此限制。
- 集群数据槽slots分配情况 (cluster_slots_assigned):集群正常运行时,默认16384个slots
- 检测下线的数据槽slots个数 (cluster_slots_fail):集群正常运行时,应该为0. 如果大于0说明集群有slot存在故障。
- 集群的分片数 (cluster_size):集群中设置的分片个数
- 集群的节点数 (cluster_known_nodes):集群中redis节点的个数
Redis响应时间监控
响应时间是衡量一个服务组件性能和质量的重要指标。使用redis的服务通常对响应时间都十分敏感,比如要求99%的响应时间达10ms以内。因redis的慢查询日志只计算命令的cpu占用时间,不会考虑排队或其他耗时。
- 最长响应时间(respond_time_max):最长响应时间的毫秒数
- 99%的响应时间长度 (respond_time_99_max)
- 99%的平均响应时间长度 (respond_time_99_avg)
- 95%的响应时间长度 (respond_time_95_max)
- 95%的平均响应时间长度 (respond_time_95_avg)
常用的成熟方案
无论哪种,要体系化,必然要考虑如下几点。
- 指标采集,即采集redis提供的metric指标,所以方案中有时候会出现Agent,比如metricBeat;
- 监控的数据持久化,只有将监控数据放到数据库,才能对比和长期监控;
- 时序化,因为很多场景都会按照时间序列去展示 - 所以通常是用时序库或者针对时间列优化;
- 可视化,比如常见的kibana,grafana等
- 按条件报警,因为运维不可能盯着看,只有引入报警配置,触发报警条件时即发出报警,比如短息提醒等;基于不同报警方式,平台可以提供插件支持等;
ELK Stack
- 采集agent: metricBeat
- 收集管道:logstash
- DB: elasticSearch
- view和告警: kibana及插件
fluent + Prometheus + Grafana
- 采集指标来源: redis-export
- 收集管道:fluentd
- DB: Prometheus
- view和告警: Grafana及插件
评论 (0)